





资 讯
自动混音技术并不是一项新技术,从上个世纪70年代开始涌现各种类型的自动混音器,以及其中的各种专利到现在转变为DSP设备内的一个功能。自动混音器的形态也正逐渐从一台独立的设备到虚拟的编程算法。虽然现在各家的软件算法,并不会公布,但我们可以通过了解自动混音器内的核心技术和原理来更好的理解和使用DSP内的自动混音功能。
为什么要用自动混音技术?

图中我们可以清晰的得到以下三点:
1. 话筒数量多
一个几十平米的会议室往往需要塞下十几只甚至更多的话筒。音响工程师调试时都会遇到一个现象:一只一只话筒调试到不啸叫,但是开启两只或更多话筒时就莫名其妙的啸叫起来。这也是音响人经常提的一个定律:打开话筒数量增加一倍,系统增益增加3dB。
即NOMG(Number of Open Microphone Gain)=10lg(NOM)。

为了能够同时打开足够多的话筒和确保系统的稳定,越多的话筒我们得调越多的系统余量。同时由于打开话筒越多拾取的环境噪音也越多,导致系统的信噪比下降,无法获得足够的语言清晰度。
2. 不注重声学装修。不论是哪种厅堂更注重肯定是视觉,装修一定要好看,大气,庄重等。会议室也不例外,且很多会议室甚至是全玻璃结构的根本不考虑扩声的需求。等到真正使用扩声时,才发现房间反射严重,根本没法获得足够的语音清晰度和传声增益。。
3. 话筒正对这音箱。会议室是一个面对面交流的地方,听者和说话者都在一个空间内,那这样也就意味着扩声扬声器覆盖的区域同时又需要话筒进行拾音,所以在会议室内几乎都会遇到话筒正对音箱的情况。这样直接导致我们无法获得足够的传声增益。
通过以上三个问题我们可以看到一个矛盾点:话筒多需要为系统留足够的余量,但建声环境和音箱话筒摆位又无法为系统提供足够的余量。如何化解这个矛盾成为关键。
第一个问题,不注重声学装修,反射严重,人们的习惯很难改正,也正是因为这点,现在会议室越来越流行采用可调指向的音柱进行扩声,从一定意义上减少了部分反射,当然这一部分内容并不是本文探讨的范畴,总之第一个问题我们几乎没什么可商量的余地,但这却是最好的解决方法;
第二个问题,话筒正对音箱可以通过MIX-MINUS的系统设计,在一定程度上得到提高,但效果有限。
摆在我们面前的只有从第三个问题出发了,既然打开话筒越多会增加更多的系统增益,那我们就想办法控制打开的话筒数量和减少因开启话筒增加而增加的增益。那我们来看一下一般的现在有哪几种解决方法:
1. 调音师现场调控
调音师是最佳的人选来控制会场的话筒和音量。但是问题是当话筒超过6只,甚至几十只话筒时,而且会议持续几个小时之久时,事情就没有那么简单了。如何来判断某个参会人员要发言也是个问题,有时调音师也无法清楚的看到每一个参会者,很容易犯错。纵使我们能找来一个很厉害的调音师能解决以上问题,但是如果我们有很多的会议室时,给每一个会议室配备一个如此高水准的调音师也是不合理,且其成本是无法承受的。
2. 会议系统
很多会议室会选择会议系统进行话筒的管理和限制。通过限制话筒开启数量确实能一定意义上减少对余量的需求。但某些会议中为了限制的数量可能会影响会议的流畅度。会议系统的音质,是让很多使用者和音响工程师所诟病的。同时会议系统往往混音一路的输出到处理设备,均衡话筒时将对所有话筒进行调整,然而实际每个话筒的均衡点都是不一样的,而且还经常会遇到,调完某个话筒,其他某个某几个话筒啸叫起来等现象。最终导致音质更差,且浪费很多调音师宝贵的时间。
3. 自动混音技术
自动根据电平开启或关闭话筒,能够自动平衡因开启话筒数量成倍而增加的系统增益.其实与第一种方式很相似,只不过此时人变成了设备.那此时由于能减少对余量的需求,且话筒采用的是鹅颈话筒的形式,最终出来的声音会比会议系统好很多.但实际上单台的自动混音器其实与会议系统类似,最终也是混音一路到处理设备进行处理。
这样的处理形式其实与会议系统一样存在问题。所以我们一般会推荐给客户使用的是带自动混音器功能的DSP设备每只话筒都可以得到相应精准的调试,这样音质最优化,同时某些具备自动混音器直接输出功能,可轻松做到MIX-MINUS,而这一点也是普通自动混音器或会议系统几乎无法实现的。且由于可以结合DSP自身丰富的功能,实现诸多会议系统的功能 如 主席优先,请求发言,摄像跟踪等等。
综上3种解决方案,会议中多话筒处理既能达到较好的音质,保证系统稳定,又能实现较多会议管理功能的最好方案是采用DSP设备的自动混音功能。了解完为什么需要使用自动混音技术后下面就自动混音技术的分类和技术进行阐述。
自动混音技术分类
从前文我们可以得到自动混音器需具2个基本要素:
1.何时及如何开启和关闭话筒;
2.如何平衡NOM增益。
从技术上可以分为两类:
Gating和Gainsharing自动混音器。
Gating自动混音器顾名思义会有一个门限来控制话筒的开关,声音超过门限则打开话筒,声音低于门限则关闭话筒。那如何来获得最佳的门限(Threshold)?
固定阈值:最简单也是最常见的就是采用一个语音触发开关或噪声门,设定一个固定的值,超过这个值则话筒开启,低于则关闭。通常这个值是可以调整的,但无法根据环境噪音自行调整,所以得到的效果往往不尽意。可参见下图:
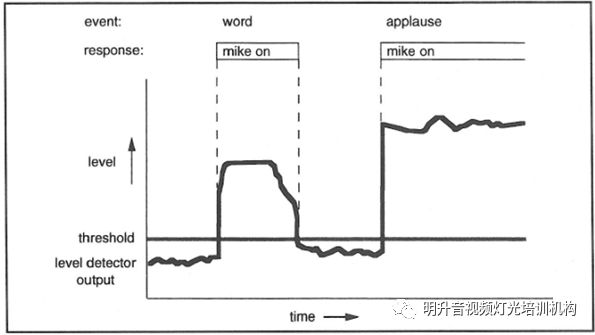
在很多情况下如果设置的太小,则环境噪音、鼓掌和某些音乐等声音很容易就可以开启话筒。设置的太高则又很容易出现吃字或声音卡壳等现象。当使用噪声门等装置还有另外一个问题就是当全体鼓掌的情况出现时,所有话筒都被打开,系统及其容易产生啸叫。由于固定阈值实现简单,成本低,很多自动混音器和软件化的自动混音器仍旧采用类似的方法来做决策,其最终的效果往往很差。
自适应阈值:由于固定阈值很难得到较好的效果,各家厂商相继推出了自己的自适应阈值电路或算法,可根据环境噪音实时得到新的阈值,最终效果的好坏也各有差异。基本示意可参见下图。
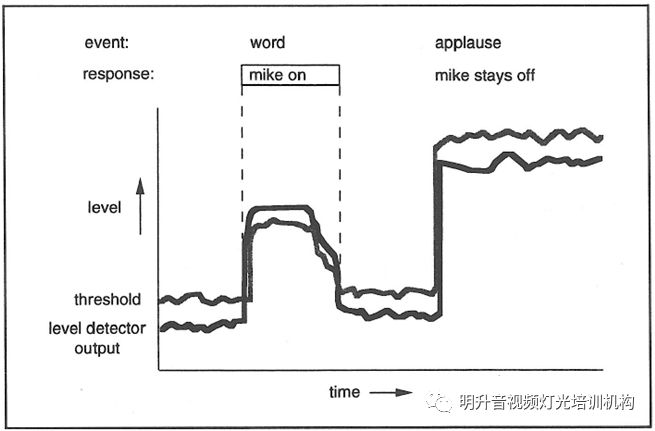
自适应阈值的工作原理各有差异,但归结起来有一下几种类型:
1.噪声感应。如给每个话筒都加一个噪声感应的话筒,作为其环境噪声的判断水平。有些采用一组话筒或一个混音器一个感应话筒的输入作为参考环境噪音水平。这种方法是最直接的思考方式,但对感应话筒的位置摆放要求较高。早期舒尔曾经出过需要匹配相应麦克风的自动混音器。
2.扫描阈值。由于噪声感应的额外投入,涌现出了各种通过扫描当前每只话筒的电平然后确定一个阈值的电路或算法。而这正是体现厂家自动混音技术优劣的技术关键点。简单的直接求平均作为阈值,也有不断向下扫描,当遇到最大的电平的通道则在该通道保持一个很短的时间,以此往复。做的不好的阈值电路和算法可能就会出现常见的“吃字”现象。当使用这种方式时的好处是显而易见的,调试人员将不需要去设置阈值,将节省大量的调试时间。
门控技术:在解决完阈值的设定问题后,实际在早期设计自动混音技术还遇到一个问题就是开关所带来的电子脉冲声音。那这也是早期限制自动混音器推广的原因之一。那目前而言主流的厂商都是采用off-attenuation的方式来实现话筒的开关。off-attenuation实际就是将开关变成了通道的衰减。我们知道0dBu的信号输出当我们衰减-40dBu以后将几乎听不到任何的声音。所以通过这种方式就很好的解决了话筒开关而带来的噪音。
NOMA(Number of Open Microphone Attenuation):前面我们讨论的主要是阈值如何确定,以及确定了阈值后话筒如何开关的技术手段。我们还有最后一个问题,多个话筒开启后增加的增益如何解决?一般而言Gating自动混音器都会采用如下的电路来实现总体增益的平衡。采用一个计数器来记录当前开启话筒的数量,然后根据数量进行相应的总增益衰减。如开启两只衰减3dB,开启四只衰减6dB。
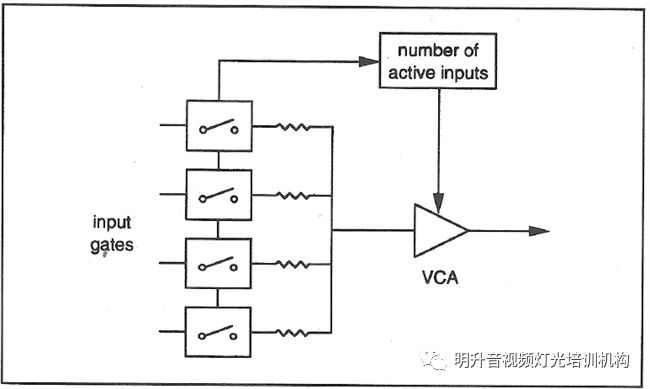
那前面我们谈的NOMG=10lg(NOM),这是一个标称上的增益增加。但是我们没有将信号的相干性考虑进去。在一个标准的会议室,不同的讲话者使用不同的话筒,信号进入各自的麦克风通道,则两者我们普遍意义上理解为“不相干信号”。
当一个讲话者同时对着距离相等的两个话筒,则在话筒端将接收到两个完全一样的信号,我们称此为“相干信号”。相干信号在电平上不一定要相等,但大小相差一定是很小的。另一个相干的例子就是当会议室的门被用力的开关,书本掉在地上,或大家的鼓掌声等很有可能在两个或多个话筒出产生类似大小的信号。
关于两个信号叠加加入相位的考虑实际我们开启话筒数量的系统增益是:

Et:总声压、电流、或电压
E1:第一个信号
E2:第一个信号
α:信号的相位角
由上我们可以得出实际两个信号的叠加是0~6dB的增益增加。基于此部分厂商在做NOMA电路时将此值开放作为可调,但是当作为可调时就增加了工程师调试时的调试参数和对技术的理解,且由于3~6dB的增加往往是较少情况出现,如果为了部分极少出现的情况而大大降低我们的系统增益是得不偿失的。所以很多厂商会采用中间默认为3dB的衰减。
这种方式带来的另外一个问题是开启多只话筒可能多的增益,可能的啸叫。则为了避免此问题我们在调试Gating自动混音器时还需要注意在FSM(反馈稳定余量)6dB的基础上再增加至少3dB的系统余量来保证系统的稳定运行。
前文所说Gating+Noma的自动混音技术是一种正向思维的解决办法,归结起来三步走:
1.话筒什么情况下开和关
2.话筒如何开和关
3.话筒开了如何平衡增益。
而Gainsharing的技术则是一种逆向思维的解决办法。
Gainsharing其实本质上是一套算法,可以简单的用下面这句话来描述,“每一路输入进行一定量的衰减,衰减量等于该路电平与所有通路电平总和之差,以dB加减。”这一套简单有效的算法由美国音频技术大拿于上世纪70年代提出,并在1976年取得专利。在专利保护的20年内只有几家授权厂商在生产基于Gainsharing的自动混音器。直到专利保护期过后才在市场上逐渐出现相关的自动混音器,也才更多的被大家所知道Gainsharing的技术。专利这把双刃剑,此处就不多谈了。我们来看看具体的实现方法。
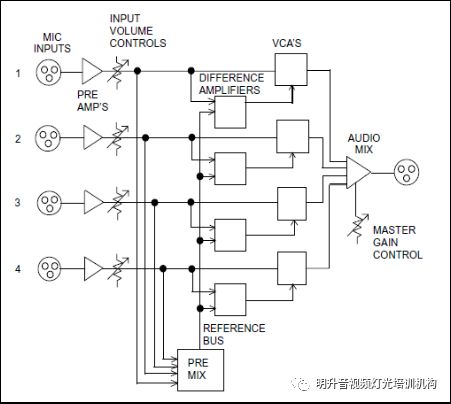
通过上图我们可以知道,通过预先混合得到总电平,然后在通过一个比较器得出每一路电平与总电平的差值,最后调整相应通道的VCA来实现增益的共享。
当所有话筒都没有人说话时,此时所有话筒拾取的都是几乎等量的环境噪音,则每个话筒都分得几乎相同的增益;
当其中一个话筒说话时,此时该话筒将得到几乎100%的增益,而其他未说话的话筒分享剩下的增益;
当有2个话筒说话时,电平越大的拿的的增益越多,电平越小的拿的的增益越少,另一种情况就是假设两者的电平一致,则两者均分几乎100%的增益,其他情况以此类推。
从中我们可以看出Gainsharing永远不会有多余的增益溢出,而是不断在分配可用增益的过程。所以从理论上可以看出,Gainsharing自动混音可以很好的辨别出相干与非相干信号,对余量的需求将会比Gating的小。那带给音频工程师的益处就是减少一定的调试工作。
Gainsharing自动混音技术面临一个问题是当话筒数量多的时候,没有说话的话筒总和起来的电平将足够大,这样有可能导致实际需要扩声的话筒被减去过多的增益。所以对于一般的增益共享自动混音器建议通道数少于16只。当然也有厂商意识到了这些问题提供相关的参数设置给到工程师配置,主要通过更改分配比例来实现。
自动混音器的选择与设计注意事项
通过上面的介绍我们了解两种自动混音器的基本原理及各自的技术特点。那在实际的项目中我们该如何选择自动混音器?这里我给出的建议是:
1.首先尽可能测试即将使用的自动混音器或技术是否能完成我们的工作,如Gating是否吃字,Gainsharing是否有更多话筒处理的能力等等。
2.根据自身技术能力选择。如Gating涉及门限,门限里面包含如何设置,启动时间,释放时间等等诸多的参数设置,则对此时需要充分了解每个设置的具体作用,那对技术人员的要求相对较高;而Gainsharing是一套自成体系的算法,则几乎没有需要你自己设置的参数,相对来说对自动混音内的技术本身了解的要求则大大降低。
3.现场系统余量的许可。当现场余量足够时则建议使用Gating自动混音技术;当现场余量不足时则可使用Gainsharing确保任何时候的系统安全。
4.积极参加各厂家的相关的培训,充分了解各参数对应到的相关技术及解决的问题。
在自动混音器系统内实际要注意的除了对自动混音技术的了解以外,同时需要确保系统在正确的增益结构链路下。由于自动混音技术是根据实时电平大小来决定话筒开关或增益量的,所以如果增益结构不对很可能导致最终工作结果并不是你想要的结果。
自动混音技术的应用和发展展望
自动混音的应用在诞生之初是为了解决演播厅等的多话筒的管理问题,由于AV工程商的介入才发展到会议室内使用。从而构建一个自由无拘束的会议环境,并且大大减少会议的管理工作。但是由于中国技术的引进以及早期的自动混音器工作效果并不良好,所以几乎在广播市场很少使用,很少有人知道会议室需要用自动混音器。但随着越来越多国外高端厂商性能及效果良好的自动混音器引进,现在越来越多的会议室正在使用自动混音器或带自动混音的DSP处理器。
实际我对自动混音技术的理解是:多话筒的自动化或智能化管理。所以任何需要用到多话筒的场合都可以使用自动混音技术。

近几年很流行的大型多人社交语言类节目,现场几十只的话筒的管理让调音师绞尽脑汁。所以这种场合就需要使用自动混音技术来减少调音师的负担。如上图的爱情学院最终就选择了基于DSP的自动混音技术结合相关DSP内的功能很好的解决了节目话筒管理的问题。

多功能剧场剧院也是需要自动混音技术的场合。这种类型的剧场剧院主要为开会服务,一年演出机会实际很少。然而现在的项目一般会按照标准剧院的模式去设计。往往造成开会时管理复杂,或总是需要专人管理。实际我们可以将此类场所看做一个大型的会议室。那会议室我们现在往往会使用DSP和DSP内部的自动混音来完成话筒管理,多功能的礼堂剧院同样可以采用这样的模式,通过合理的系统搭建实现无人值守的会议。
其他更多的应用这里不做一一列举,记住自动混音帮助我们管理话筒,在任何的多话筒项目中你都可以考虑考虑。
目前自动混音技术基本都市融合到各家的DSP内作为一个功能,所以在谈发展时我们应当站在DSP的角度去考虑技术的发展。所以几个小点是我认为可能的方向:
1.基于语音识别的自动混音技术。
就目前所能见到的自动混音技术都是纯粹基于电平来进行管理的,这样或多或少会出现误判。而当有语音识别的自动混音技术出现时,则可以很精准的启动和关闭话筒。当然我这里说的语音识别并不是大家所熟悉的SIRI或科大讯飞这些,这一类是非实时的处理且允许较长的响应时间,而在DSP内所谈的语音识别技术是在毫秒级的快速判断,且准确度必须很高,否则带来的就是糟糕的会议体验。目前已有顶尖的DSP厂商能实现这种类型的语音识别,未来可期。
2.加入会议管理的自动混音技术。
目前而言自动混音技术主要场合是自由发言会议的场合。根据国内的实际情况,对会议管理要求更多的功能,则此时能通过开放式DSP内部编程来实现部分如优先等功能,但更为复杂的实现仍需要借助第三方来实现。所以加入会议管理的自动混音也可能是一个课题。
正如自动混音技术是为广播事业而诞生最终被AV集成商青睐,当技术发展到足够成熟能够很好的完成它本应解决的问题,技术的应用则又会有新的发展。我们通过很好的理解技术的本源来更好的理解我们的产品以及为客户提供更优质的沟通环境。
